As a Data Scientise programmer, you have to work most on the Python Dictionary and lists. You use it with Pandas for creating a beautiful and exporting table for your data present as a list and the dictionary. But converting dictionary keys and values as Pandas columns always leads to time consuming if you don't know the concept of using it.

In this entire tutorial of "how to ", you will learn how to convert python dictionary to pandas dataframe in simple steps. In this tutorial we will learn how to create or add new column to dataframe in python pandas. Creating a new column or variable to the already existing dataframe in python pandas is explained with example.

Adding a new column or variable to the already existing dataframe in python pandas with an example. Creating the new column has four different methods and adding a variable can be done by two different methods. But pandas data frame can be also created from the list, dictionary, list of lists, list of dictionaries, dictionary of ndarray/lists, etc.

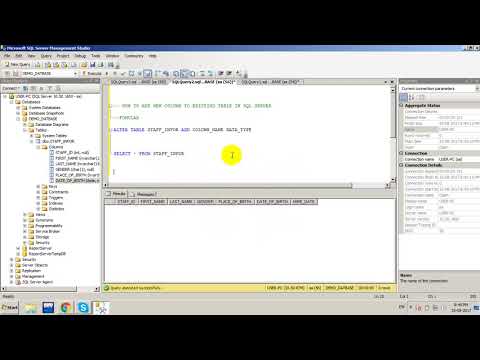
Before we start discussing how to add a new column to an existing data frame we require a pandas data frame. Next we create a new python dictionary containing the month names with values from the pandas series as the indices of the dictionary. Then we use a map function to add the month's dictionary with the existing Data Frame to get a new column. The map function takes care of arranging the month names with the indices of the dictionary.
Pandas Data Frame is a two-dimensional data structure, i.e., data is aligned in a tabular fashion in rows and columns. It can be created using python dict, list, and series etc. In this article, we will see how to add a new column to an existing data frame. The keys of the dictionary are the DataFrame's column labels, and the dictionary values are the data values in the corresponding DataFrame columns.

The values can be contained in a tuple, list, one-dimensional NumPy array, Pandas Series object, or one of several other data types. You can also provide a single value that will be copied along the entire column. Pandas library in Python has a really cool function called map that lets you manipulate your pandas data frame much easily.

Pandas' map function lets you add a new column with values from a dictionary if the data frame has a column matching the keys in the dictionary. Adding a New Column Using keys from Dictionary matching a column in pandas. It is a versatile function to convert a Pandas dataframe or Series into a dictionary. In most use cases, Pandas' to_dict () function creates dictionary of dictionaries. It uses column names as keys and the column values as values.

It creates a dictionary for column values using the index as keys. The .assign() function returns a new object with all original columns as well as the new ones. Existing columns that are re-assigned will be overwritten.

If the values are callable, they are computed on the dataframe and assigned to the new columns. If you need a refresher on loc , check out my tutorial here. Pandas' loc creates a boolean mask, based on a condition.
Sometimes, that condition can just be selecting rows and columns, but it can also be used to filter dataframes. These filtered dataframes can then have values applied to them. This creates a dictionary for all columns in the dataframe.

"' Iterate over all the key value pairs in dictionary and call the given callback function () on each pair. In this tutorial, we will look at how to create a pandas dataframe column with values based on a condition. We will look at some examples to demonstrate the methods mentioned. Once added, you can select rows from pandas dataframe based on condition to check if the empty column is added appropriately. Empty columns are added to the pandas dataframe as a placeholder to add values at a later point in time. The ALTER query lets you create and delete separate elements in nested data structures, but not whole nested data structures.

To add a nested data structure, you can add columns with a name like name.nested_name and the type Array. A nested data structure is equivalent to multiple array columns with a name that has the same prefix before the dot. You can use the Python dictionary (key-value pair) to add a new column in an existing data frame. In this method, you must use the new column as the key and an existing column as the value. This method allows you to assign a new column into an existing data frame.

Here, the patient_name column is passed as a parameter, and its corresponding list of values is equated against it. Depending on the need and the requirement, you can choose one of the methods specified which are more suitable. Here we created a dictionary by zipping the a list of values and existing column 'Name'. Then set this dictionary as the new column 'ID' in the dataframe. In the code above you can see first, I am extracting all dictionary items and iterating it with code and name of the company stocks. After that, I am appending all the changes in the rows list.

Then you can easily convert this list into DataFrames using pd.DataFrame() function. Again, the dictionary keys are the column labels, and the dictionary values are the data values in the DataFrame. To the existing dataframe, lets add new column named "Address" to the mentioned position using insert() function. Insert() function creates new column to the specific position as shown below.

In other methods, the new column is created at the end of the dataframe. With the DataFrame.insert method, you can add a new column between existing columns instead of adding them at the end of the pandas DataFrame. To summarize, you've learned how to add empty columns to pandas dataframe. These empty columns are used as a placeholder to denote the missing values to which the values can be added later. The keys and values of the dictionary are converted to two columns of the dataframe with the column names given in the options columns.

We will introduce the method to convert the Python dictionary to Pandas datafarme, and options like having keys to be the columns and the values to be the row values. We could also convert the nested dictionary to dataframe. However, there are instances when I just have a few lines of data or some calculations that I want to include in my analysis.

In these cases it is helpful to know how to create DataFrames from standard python lists or dictionaries. The basic process is not difficult but because there are several different options it is helpful to understand how each works. I can never remember whether I should use from_dict, from_records, from_itemsor the default DataFrameconstructor. Normally, through some trial and error, I figure it out. Since it is still confusing to me, I thought I would walk through several examples below to clarify the different approaches.

At the end of the article, I briefly show how this can be useful when generating Excel reports. A column can be created with dictionary encoding in effect by applying thedict data handling property to the column during type creation (using/create/type). An existing column can be converted to usedictionary encoding by modifying the column and applying the dict property (using /alter/table).

Each value has an array of four elements, so it naturally fits into what you can think of as a table with 2 columns and 4 rows. The rename() function can be used for both row labels and column labels. Provide a dictionary with the keys the current names and the values the new names to update the corresponding names. To add empty columns from a list, you can check Get the Column Name of pandas dataframe and use those columns in the list with additional columns. Reindex method conforms the dataframe to a new index as specified. When adding a new column, the reindex method conforms the dataframe to the index with new columns and returns a new dataframe with the changed index.

In this tutorial, you'll learn different methods to add empty columns to pandas dataframe. A dictionary, sometimes called an association, is a mapping defined by positional correspondence between a domain list of keys and a co-domain list of values. Operator – read "bang" – in contrast with the syntactic form for lists.

Each of these methods has a different use case that we explored throughout this post. I need to create a new column new_col searching if the string contains in col_1. If so, I need to get the dictionary key and place it in the new column. I have a Pandas Dataframe and want to add the data from a dictionary uniformly to all rows in my dataframe. Currently I loop over the dictionary and set the value to my new columns. Another trick is to create a dictionary to add a new column in Pandas DataFrame.

We can use the existing columns as Key to the dictionary and assign values respectively to the new column. This method returns a new object with all original columns in addition to new ones. All the existing columns that are re-assigned will be overwritten. Create a dictionary with keys as the values of new columns and values in dictionary will be the values of any existing column i.e. It is the list of all the buying and selling signals for a particular stock.
The above list has a dictionary of dictionary with the name as the pattern as the key. The question is how can you create a data frame with the column name as signal, date, code and company name. A tabular, column-mutable dataframe object that can scale to big data. The data in SFrame is stored column-wise, and is stored on persistent storage (e.g. disk) to avoid being constrained by memory size. Each column in an SFrame is a size-immutableSArray, but SFrames are mutable in that columns can be added and subtracted with ease. An SFrame essentially acts as an ordered dict of SArrays.

The most important and only mandatory parameter of .astype() is dtype. If you pass a dictionary, then the keys are the column names and the values are your desired corresponding data types. As you can see, .dtypes returns a Series object with the column names as labels and the corresponding data types as values.
In most cases, you'll use the DataFrame constructor and provide the data, labels, and other information. You can pass the data as a two-dimensional list, tuple, or NumPy array. You can also pass it as a dictionary or Pandas Series instance, or as one of several other data types not covered in this tutorial. In this table, the first row contains the column labels (name, city, age, and py-score). In this tutorial, we saw several options to map, replace, update and add new columns based on a dictionary in Pandas.

In this article, you have learned how to remap column values with Dict in Pandas DataFrame using the DataFrame.replace() and DataFrame.map(). With DataFrame.replace(), remap none or nan column values, remap multiple column values, and same values. Also, DataFrame.map() function, you have learned pandas remap values in a column with a dictionary two approaches. While working with data in Pandas DataFrame, we perform an array of operations on the data as part of clean-up or standardization to get the data in the desired form. Let's discuss several ways with examples to remap values in the DataFrame column with a dictionary. We are often required to remap a Pandas DataFrame column values with a dictionary , you can achieve this by using DataFrame.replace() method.

The DataFrame.replace() method takes different parameters and signatures, we will use the one that takes Dictionary to remap the column values. As you know Dictionary is a key-value pair where the key is the existing value on the column and value is the literal value you wanted to replace with. Let us say you have pandas data frame created from two lists as columns; continent and mean_lifeExp. In this section, you'll learn how to add multiple empty columns to the pandas dataframe at once. This sample dataframe is used to demonstrate adding blank columns to the dataframe.

We will use pandas dictionary comprehension with concat to combine all dictionaries and then pass the list to give new column names. Most of you will notice that the order of the columns looks wrong. The issue is that the standard python dictionary does not preserve the order of its keys. If you want to control column order then there are two options. Recall that applying flip to a nested list creates a copy of the original list in which the data has been reorganized. When a column dictionary is considered as a two-dimensional entity it is rectangular, since its column lists all have the same count.

Recall that every dictionary is constructed from a list of keys and a list of values. A column dictionary is further required to have a rectangular list of values – i.e., a list of lists of the same length. What should happen when the domains lists are not identical? First, the domain of the resulting dictionary is the union of the domains – i.e., the union of the key lists.

For items in the common domain – i.e., the intersection of the keys lists, we already know we should apply the operation value-with-value. In this article, I will use examples to show you how to add columns to a dataframe in Pandas. There is more than one way of adding columns to a Pandas dataframe, let's review the main approaches. In this example, we are going to create a DataFrame from a list of dictionaries with three rows and three columns, containing student subjects. After creating the data with a list of dictionaries, we have to pass the data to the createDataFrame() method.





No comments:
Post a Comment
Note: Only a member of this blog may post a comment.